Reading Note of the Paper "A Survey on Neural Speech Synthesis"
Information of the Original Paper: Tan, Xu, et al. “A Survey on Neural Speech Synthesis”. arXiv preprint arXiv:2106.15561.
Brief Intro
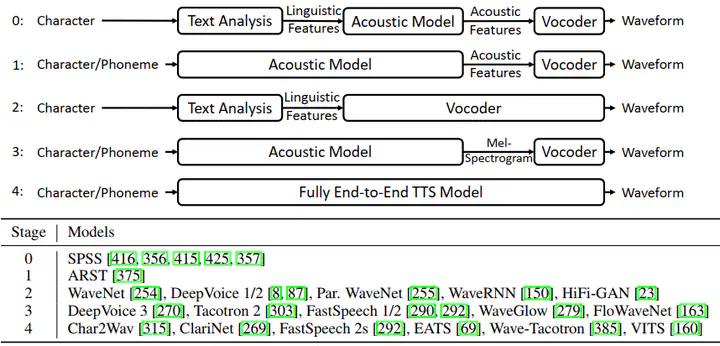
Text-to-speech (TTS), also known as speech synthesis, aims to synthesize intelligible and natural speech from text. Neural TTS adopts DNNs as the model backbone for speech synthesis.
There are three key components in neural TTS. The text analysis module converts a text sequence into linguistic features, the acoustic models generate acoustic features from linguistic features, and then the vocoders synthesize waveform from acoustic features.
Content Access
Please click here to access the content of the blog from my Gitbook.
Yanyun Wang
MPhil Student
My research interests include adversarial/backdoor attack, adversarial training, and LLM alignment.